Как получить список уникальных значений
В этой статье описывается, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для разных наборов данных. Вы также узнаете, как быстро получить единый список с помощью расширенного фильтра Excel и как извлечь уникальные записи с помощью средства удаления дубликатов.
В нескольких недавних статьях мы обсуждали различные методы подсчета и поиска уникальных значений в Excel. Если у вас была возможность прочитать эти руководства, вы уже знаете, как получить этот список с помощью идентификации, фильтрации и копирования. Но это немного долго и далеко не единственный способ извлечь уникальные значения в Excel. Вы можете сделать это намного быстрее, используя специальную формулу. А сейчас я покажу вам этот и еще несколько приемов.
- Формулы для уникальных значений в столбце.
- Как извлечь уникальные + 1-е появление дубликатов.
- Если вы хотите игнорировать пустые ячейки.
- Выберите уникальный, он чувствителен к регистру.
- Подбор уникальных значений по условию.
- Как извлечь уникальные значения из диапазона.
- Используем встроенный инструмент для удаления дубликатов.
- Список уникальных с использованием расширенного фильтра.
- Уникальное извлечение данных с Duplicate Remover.
Базовые формулы для получения уникальных значений.
Чтобы не было путаницы, давайте сначала договоримся о том, что мы называем уникальными значениями в Excel.
Уникальные значения — это значения, которые появляются в списке только один раз. Например:
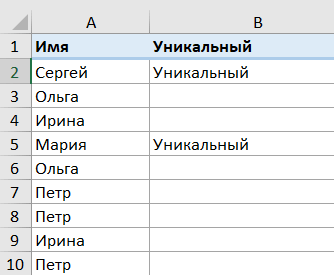
Чтобы получить список уникальных значений в Excel, используйте одну из следующих формул.
Формула для значений одиночного массива (заполняется нажатием Ctrl+Shift+Enter):
=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$10, ПОИСКПОЗ(0, СЧЁТЕСЛИ($B$1:B1,$A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10 , $A$2) :$ $10)1); 0)); «»)
Также можно использовать обычную формулу (вводится нажатием Enter):
=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$10, ПОИСКПОЗ(0,ИНДЕКС(СЧЁТЕСЛИ($B$1:B1, $A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10, $ A$2) :$A$10)1);0;0);0)); «»)
В приведенных выше формулах используются следующие ссылки:
- A2: A10 — исходный список данных.
- B1 — это верхняя ячейка одного списка минус одна строка. В этом примере мы начинаем создавать список уникальных в B2, и мы пишем B1 в формулу (B2 — 1 строка = B1). Если ваш список начинается, скажем, с ячейки C3, измените $B$1:B1 на $C$2:C2.
Примечание. Поскольку формула ссылается на ячейку над первой ячейкой сгенерированного списка, которая обычно является заголовком столбца (B1 в этом примере), убедитесь, что ваш заголовок имеет уникальное имя, которое не появляется больше нигде в этом столбце.
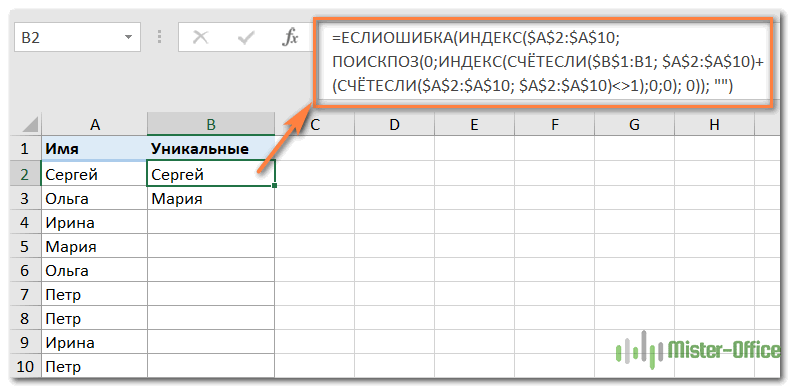
В этом примере мы извлекаем уникальные имена из столбца A (точнее, в диапазоне A2:A10), а на следующем снимке экрана показана формула в действии:
Это наш план действий:
- Измените любую из формул, чтобы она соответствовала вашему диапазону данных.
- Введите его в первую ячейку, с которой будет начинаться формирование списка (в данном примере В2).
- Если вы используете формулу массива, нажмите Ctrl + Shift + Enter. Если вы выберете нормальный, просто нажмите клавишу Enter.
- Скопируйте столько, сколько необходимо, перетащив маркер заполнения. Поскольку обе формулы заключены в функцию ЕСЛИОШИБКА, их можно копировать и вставлять. Он не испортит ваши данные какими-либо ошибками, независимо от того, сколько уникальных значений будет возвращено.
Как извлечь различные значения.
Различные значения: появляются в списке данных хотя бы один раз. Все они уникальны и являются первым вхождением повторяющихся значений.
Например:
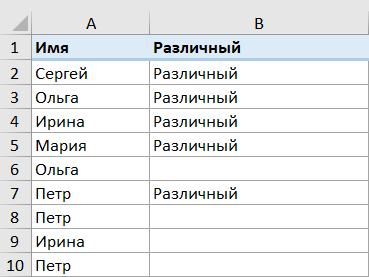
Чтобы получить их список в Excel, используйте следующие формулы.
Формула массива (требуется нажатие Ctrl + Shift + Enter):
{=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13, СОВПАДЕНИЕ(0, СЧЁТ.ЕСЛИ($B$1:B1, $A$2:$A$13), 0)); «»)}
или вы можете сделать это так:
{=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13, МАЛЕНЬКИЙ(ЕСЛИ(КОНЕЦ(ПОИСКПОЗ($A$2:$A$13,$B$1:B1,0))), СТРОКА($A$1:$A $15) ;»»);а));»»)}
Обычная формула:
=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13, ПОИСКПОЗ(0, ИНДЕКС(СЧЕТ.ЕСЛИ($B$1:B1, $A$2:$A$13), 0, 0), 0)); «»)
Где:
- A2:A13 — это список шрифтов.
- B1 — это ячейка над первой ячейкой одиночного списка. В этом примере отдельный список начинается с ячейки B2 (это первая ячейка, в которую вы вводите формулу), поэтому он ссылается на B1.
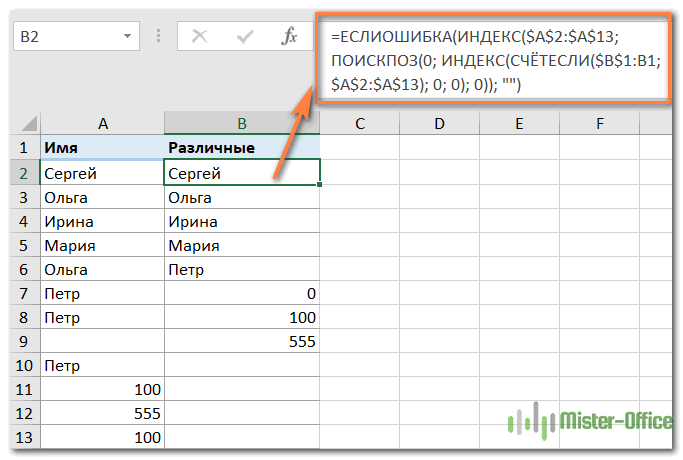
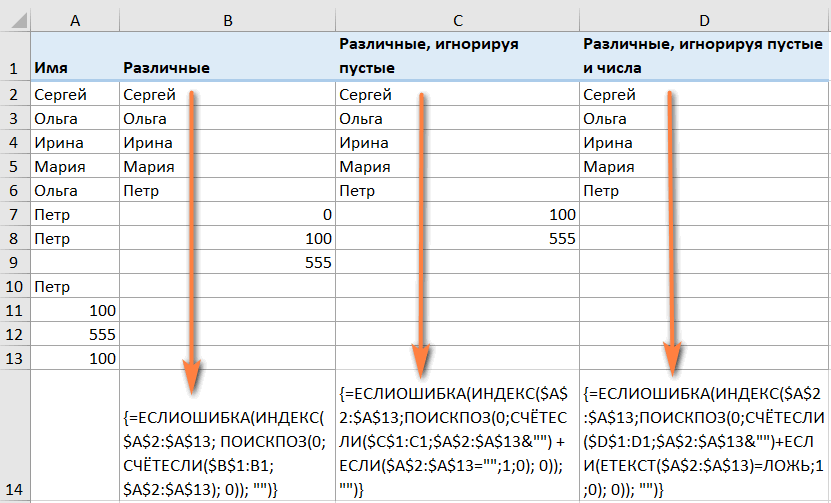
Как извлечь значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, только что рассмотренная формула будет возвращать ноль для каждой пустой строки, что может быть проблемой. Это то, что вы видите на скриншоте выше. Чтобы исправить это, давайте внесем несколько небольших изменений.
Формула массива для извлечения различных значений, исключая пустые ячейки:
{=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13; СОВПАДЕНИЕ(0;СЧЁТ.ЕСЛИ($C$1:C1;$A$2:$A$13&»») + ЕСЛИ($A$2:$A $13=»» ;1;0);0)); «»)}
Аналогичным образом можно получить список различных значений, исключая пустые ячейки и ячейки с числами:
{=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13; СОВПАДЕНИЕ(0;СЧЁТ.ЕСЛИ($D$1:D1;$A$2:$A$13&»») + ЕСЛИ(ETEXT($A$2: $A$13) =ЛОЖЬ;1;0);0)); «»)}
Помните, что в приведенных выше формулах A2:A13 — это исходный список, а B1 — ячейка непосредственно над первой позицией в сгенерированном списке.
На этом снимке экрана показан результат выбора:
Может быть кому-то будет полезна другая формула –
=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$13, АГРЕГАТ(15,6,(СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1) / (ПОИСКПОЗ($A$2: $A) $13;$A$2:$A$13;0)=СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1); СТРОКА($A$2:$A2)));»»)
Работает с числами и текстом, игнорирует пустые ячейки.
Как извлечь отдельные значения с учетом регистра в Excel
При работе с данными, чувствительными к регистру, такими как пароли, имена пользователей или имена файлов, вы можете захотеть перечислить отдельные значения, включая прописные и строчные буквы.
Для этого используйте формулу массива, где A2:A10 — исходный список, а B1 — ячейка над первой ячейкой отдельного списка.
Формула массива для получения разных значений с учетом регистра (требуется нажатие Ctrl+Shift+Enter)
{=ЕСЛИ.ОШИБКА(ИНДЕКС($A$2:$A$10, ПОИСКПОЗ(0, ЧАСТОТА(ЕСЛИ(ТОЧНО($A$2:$A$10, ТРАНСП($B$1:B1))), ПОИСКПОЗ(СТРОКА($A $2: $A$10); СТРОКА($A$2:$A$10)); «»); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10))); 0)); «»)}
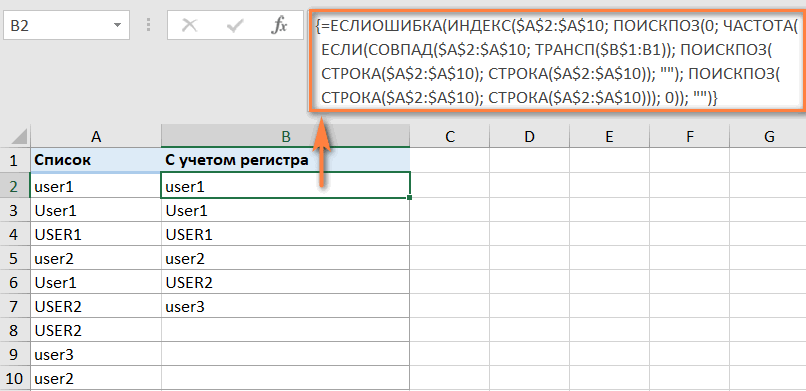
Как видите, при выборе здесь имеет значение регистр.
Отбор уникальных значений по условию.
Представим, что у нас есть таблица с данными о продажах. Нам нужно определить, какие товары заказал конкретный клиент.
Сначала мы выберем из таблицы только те строки, которые удовлетворяют заданным условиям, затем из этих строк выберем уникальные названия товаров.
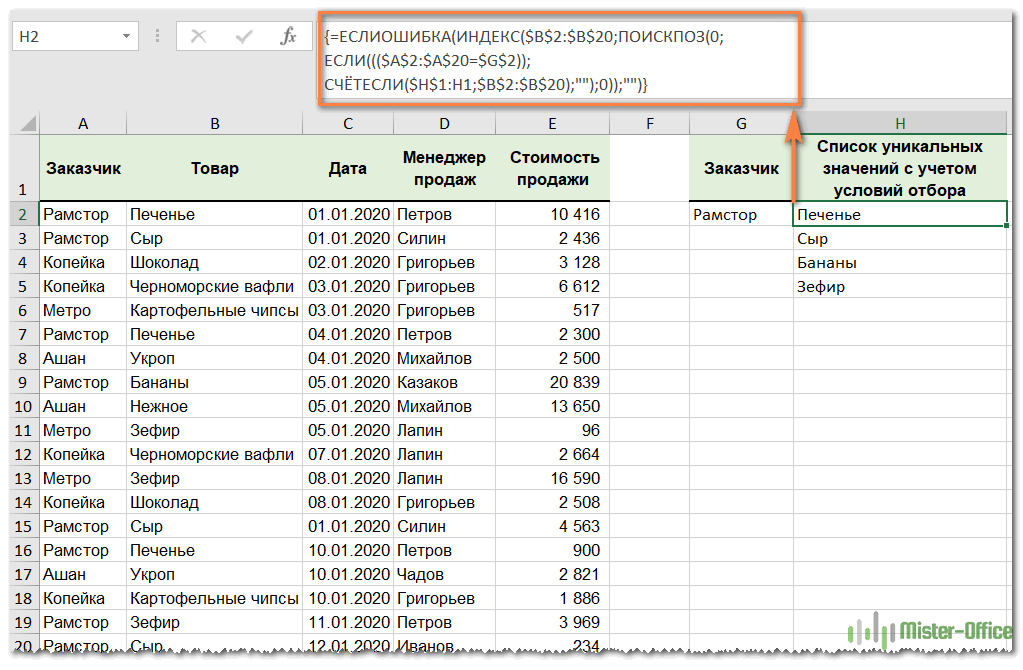
В ячейке G2 указываем нужного нам клиента, а в H2 пишем такую формулу массива:
{=ЕСЛИ.ОШИБКА(ИНДЕКС($B$2:$B$20, ПОИСКПОЗ(0,ЕСЛИ((($A$2:$A$20=$G$2)), СЧЁТЕСЛИ($H$1:H1,$B $2: $B) $20);»»);0));»»)}
Не забывайте, что формулу массива нужно ввести в ячейку EXCEL, одновременно нажав CTRL+SHIFT+ENTER. Скопируйте его в столбец, используя обработчик заполнения. Получаем список из четырех позиций.
Усложним задачу. Определим список не только для этого клиента, но и для конкретного администратора.
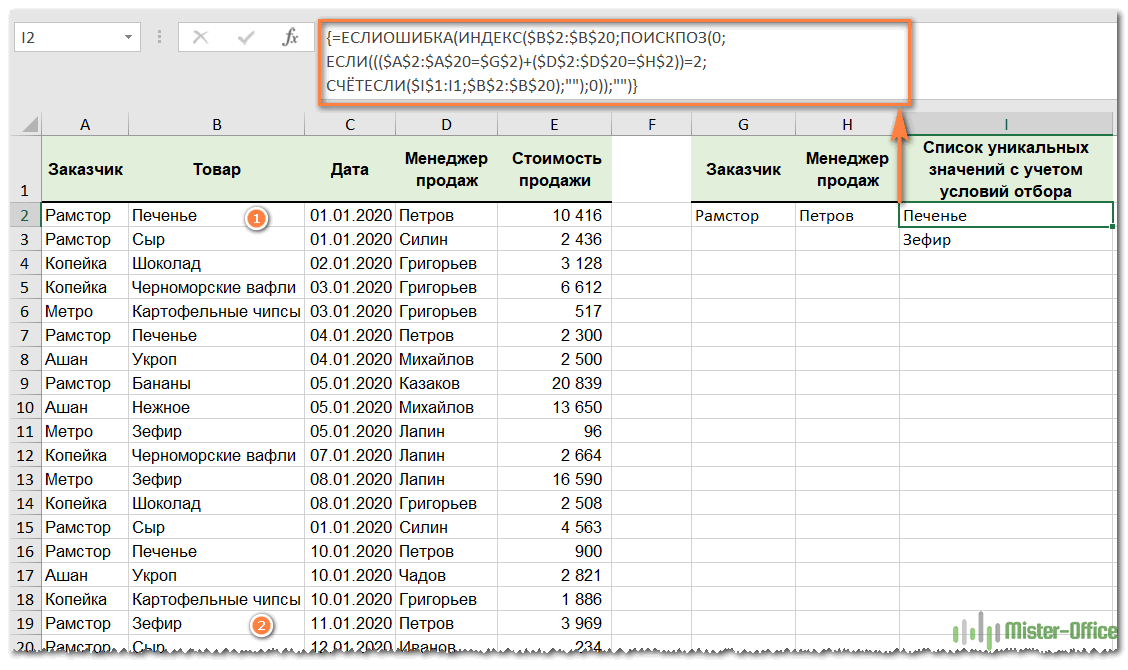
Вот формула нашего массива:
{=ЕСЛИ.ОШИБКА(ИНДЕКС($B$2:$B$20,ПОИСКПОЗ(0, ЕСЛИ((($A$2:$A$20=$G$2)+($D$2:$D$20=$H$2))= 2;СЧЁТЕСЛИ($I$1:I1;$B$2:$B$20);»»);0));»»)}
Как видите, продуктов всего два. В расчете участвуют только те строки, которые удовлетворяют одновременно двум условиям: название компании и имя администратора должны совпадать. Только из них мы извлекаем уникальные названия продуктов.
Если условий больше, нужно просто добавить соответствующие критерии в функцию ЕСЛИ и изменить число с 2 на 3 и более (в зависимости от количества условий).
Извлечь уникальные значения из диапазона.
Формулы, которые мы описали выше, позволяют сгенерировать список значений из данных в определенном столбце. Но много раз мы говорим о нескольких столбцах, то есть о диапазоне данных. Например, вы получили несколько списков товаров из разных файлов и расположили их в соседних столбцах.
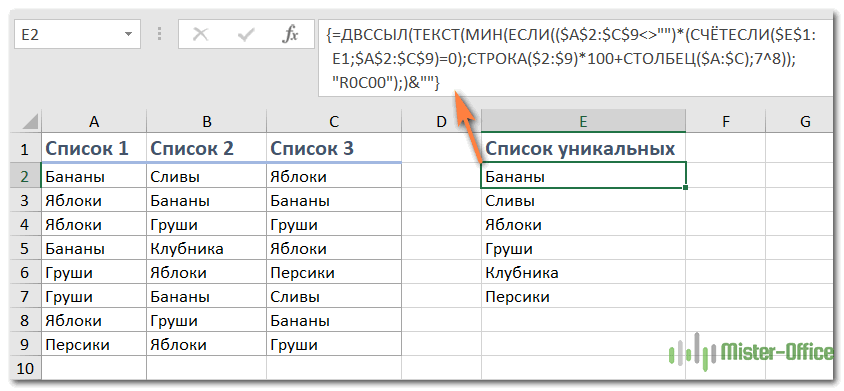
Используйте формулу массива
{=ДВССЫЛ(ТЕКСТ(МИН(ЕСЛИ($A$2:$C$9″»)*(СЧЁТЕСЛИ($E$1:E1,$A$2:$C$9)=0), СТРОКА ($2: $ 9))*100 + СТОЛБЦ($A:$C);7^8));»R0C00″);)&»»}
Здесь A2:C9 обозначает диапазон, из которого вы хотите извлечь уникальные значения. E1 — это первая ячейка в столбце, куда вы хотите поместить результат. $2:$9 указывает на строки, содержащие данные, которые вы хотите использовать. $A:$C указывает на столбцы, из которых вы извлекаете данные. Пожалуйста, обменяйте их на свои.
Нажмите Shift + Ctrl + Enter, а затем перетащите маркер заполнения, чтобы выделить отдельные значения, пока не останутся пустые ячейки.
Как видите, извлекаются все уникальные и первые вхождения дубликатов.
Встроенный инструмент удаления дубликатов.
Начиная с Excel 2007, функция удаления дубликатов является стандартной. Вы можете найти его на вкладке «Данные» > «Удалить дубликаты.
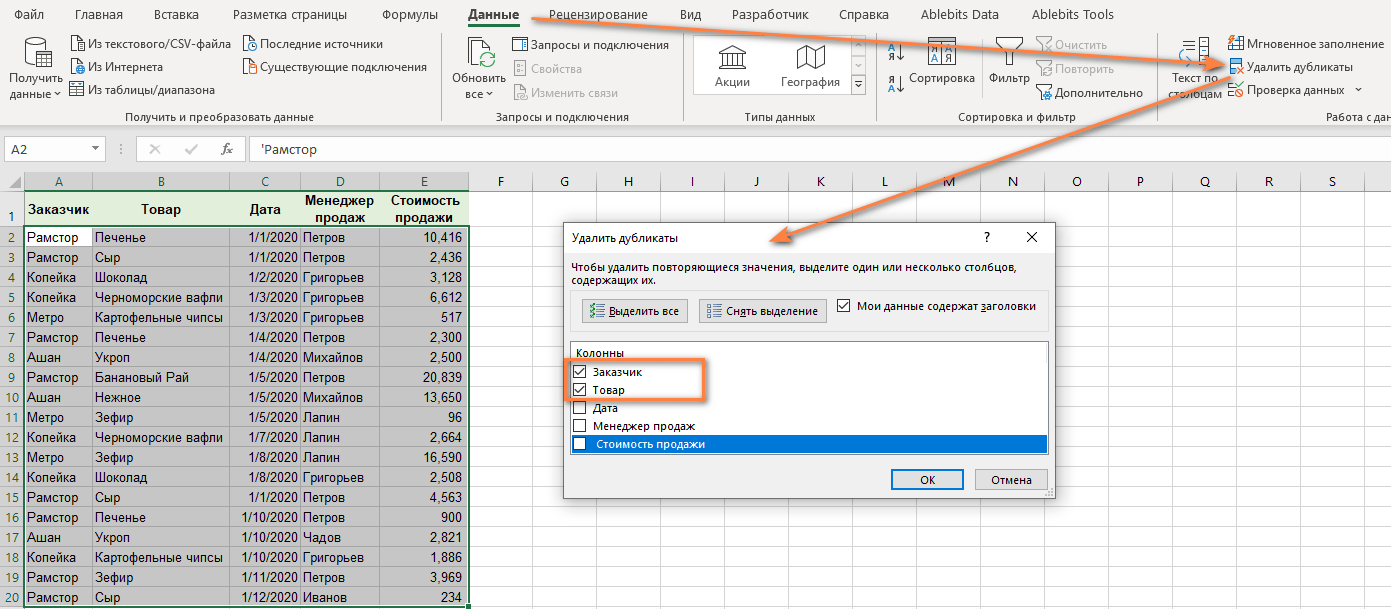
Вы должны использовать флажок, чтобы указать столбцы, в которых вы хотите найти и удалить повторяющиеся значения. Если сделать как на скриншоте, то в таблице останутся только уникальные пары «Клиент — Товар». Остальные будут удалены. Если вы включите только флажок «Клиент», для каждого клиента будет только одна строка и т д
Использование расширенного фильтра.
Если вы не хотите тратить время на расшифровку хитросплетений загадочных формул, вы можете быстро получить список уникальных значений с помощью расширенного фильтра. Подробные инструкции приведены ниже.
- Выберите столбец данных, из которого вы хотите извлечь отдельные значения.
- Перейдите на вкладку «Данные» > группу «Сортировка и фильтр» и нажмите кнопку «Еще» .
- В диалоговом окне «Расширенный фильтр» выберите следующие параметры:
- Установите флажок Копировать в другое место .
- В поле «Диапазон источника» убедитесь, что он указан правильно.
- В параметре Поместить результат в.. укажите верхнюю ячейку целевого диапазона. Обратите внимание, что на текущий лист можно копировать только отфильтрованные данные.
- Выберите «Только уникальные записи».
- Наконец, нажмите OK и проверьте результат.
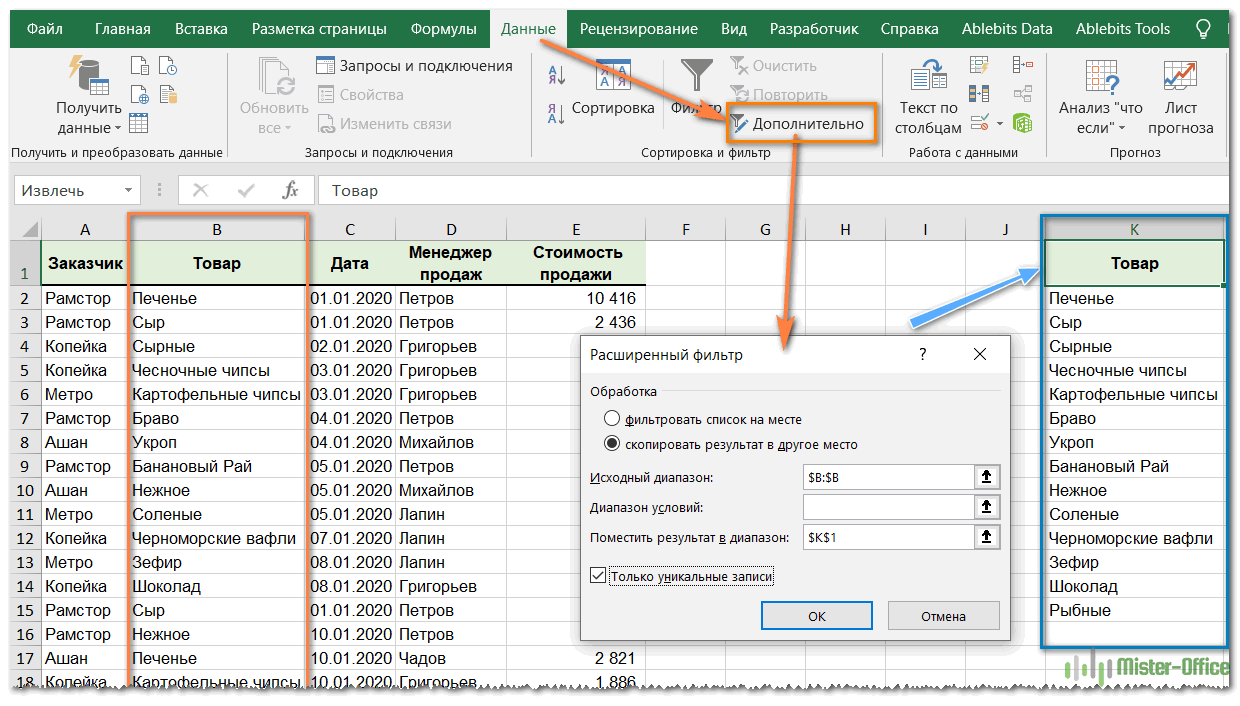
Как видите, мы проверяем столбец B, а затем помещаем список найденных уникальных элементов в столбец K.
Обратите внимание, что хотя параметр расширенного фильтра называется «Только уникальные записи», он извлекает разные значения, то есть уникальные и первые вхождения дубликатов.
Теперь немного усложним задачу.
Если вы хотите искать записи не в одном, а в нескольких столбцах, вы можете сначала «вставить» их с помощью функции СЦЕПИТЬ.
= СЦЕПИТЬ (A2, B2)
Запишите это в столбце F и скопируйте вниз. Получаем вспомогательный столбец.
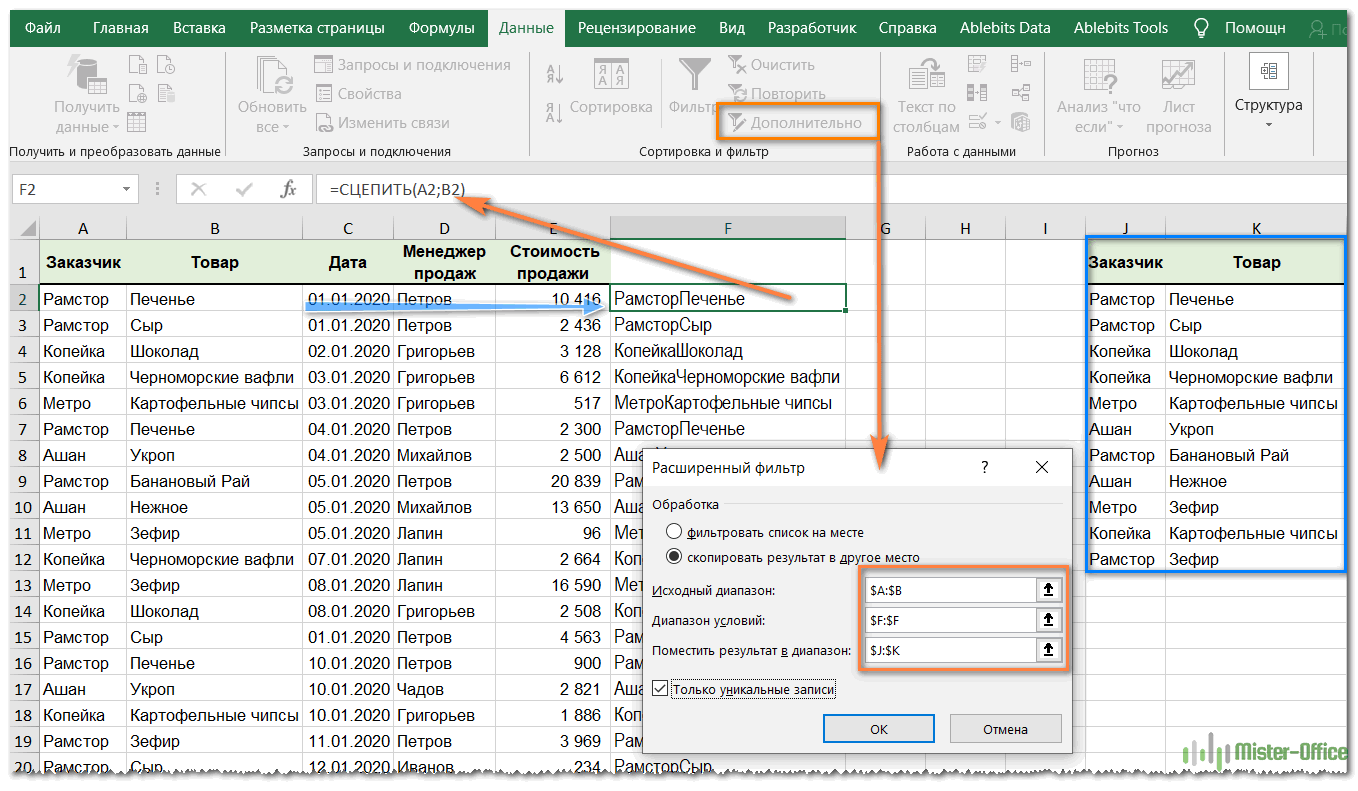
Мы по-прежнему выбираем данные в качестве начального диапазона, из которого извлекаем уникальные значения. Теперь это две колонки: А и Б.
Но по-прежнему мы можем искать только уникальные в столбце. Для этого будет полезен вспомогательный столбец F с объединенными данными. Затем указываем его в поле «Диапазон условий».
Все остальное аналогично предыдущему примеру.
В результате мы получили все имеющиеся в таблице комбинации «Клиент — Товар» на основе данных вспомогательного столбца F.
Я думаю, вы понимаете, что аналогичные действия можно производить и с тремя столбцами (например, Фамилия — Имя — Отчество). Главное условие — исходный диапазон должен быть непрерывным, то есть все столбцы должны быть смежными.
Как видите, формулы здесь не нужны. Однако при изменении исходных данных все манипуляции придется повторять заново.
Извлечение уникальных значений с помощью Duplicate Remover.
В заключительной части этого урока я покажу вам интересное решение для поиска и извлечения различных и уникальных значений в таблицах Excel. Это решение сочетает в себе универсальность формул Excel с простотой расширенного фильтра. Кроме того, здесь есть несколько уникальных особенностей:
- Найдите и извлеките уникальные или отличные значения на основе записей в одном или нескольких столбцах.
- Найдите, выделите и скопируйте уникальные значения в любое другое место в той же или другой книге Excel.
Теперь давайте посмотрим, как работает инструмент Duplicate Remover.
Предположим, у вас есть большая таблица, созданная путем объединения данных из нескольких других таблиц. Очевидно, что она содержит много повторяющихся строк, и ваша задача состоит в том, чтобы извлечь уникальные строки, встречающиеся в таблице только один раз, или разные строки, включая уникальные экземпляры и первые дубликаты. В любом случае, с плагином Duplicate Remover работа выполняется в несколько шагов.
- Выберите любую ячейку в исходной таблице и нажмите кнопку DuplicateRemover на вкладке AblebitsData в группе Dedupe.
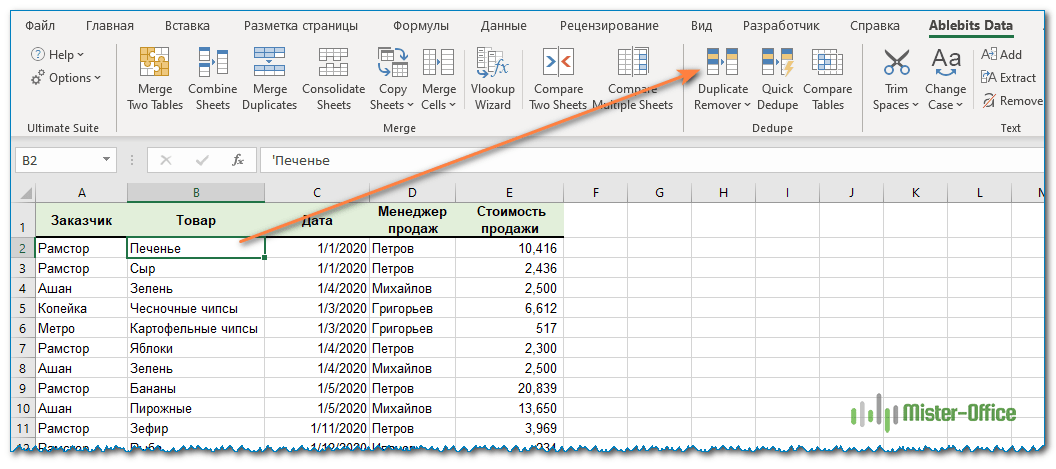
Запустится мастер дедупликации и выберет всю таблицу. Итак, просто нажмите «Далее», чтобы перейти к следующему шагу.
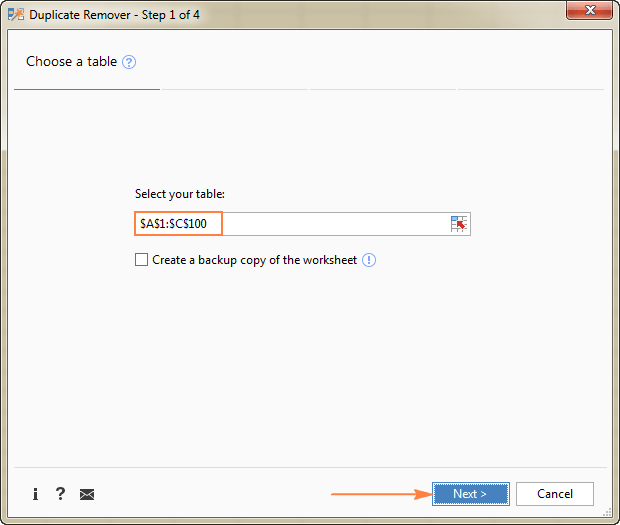
- Выберите тип значения, которое вы хотите найти, и нажмите «Далее :
- уникальный
- уникальный + 1 появление (несколько)
В этом примере мы хотим извлечь отдельные строки, которые появляются хотя бы один раз в исходной таблице, поэтому мы выбираем параметр «Уникальное + 1-е вхождение:
В примечании. Как вы можете видеть на скриншоте выше, есть также 2 варианта поиска дубликатов. Просто имейте это в виду, если вам нужно искать дубликаты в таблице.
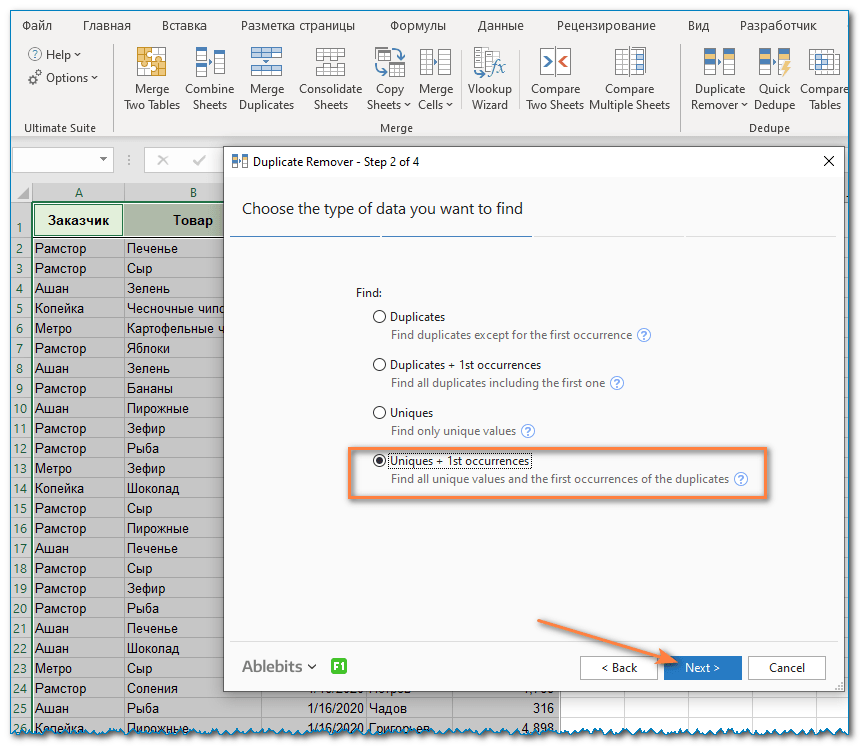
- Выберите один или несколько столбцов для поиска уникальных значений.
В этом примере мы хотим удалить все повторяющиеся значения на основе значений в 2-х столбцах (клиент и продукт), поэтому выбираем только нужные нам столбцы.
В нашем случае таблица имеет заголовок, поэтому установите флажок Моя таблица имеет заголовки.
Думаю, нам не нужны пустые строки, которые могут случайно получиться при объединении данных из разных таблиц. Поэтому ставим еще галочку Пропускать пустые ячейки.
Если в наших логах вдруг появляются лишние пробелы, то думаю стоит их игнорировать. Поэтому мы также проверяем Игнорировать лишние пробелы.
Кроме того, наш поиск будет нечувствительным к регистру, то есть при сравнении данных мы не будем различать верхний и нижний регистр. Поэтому мы не касаемся опции сопоставления регистра.
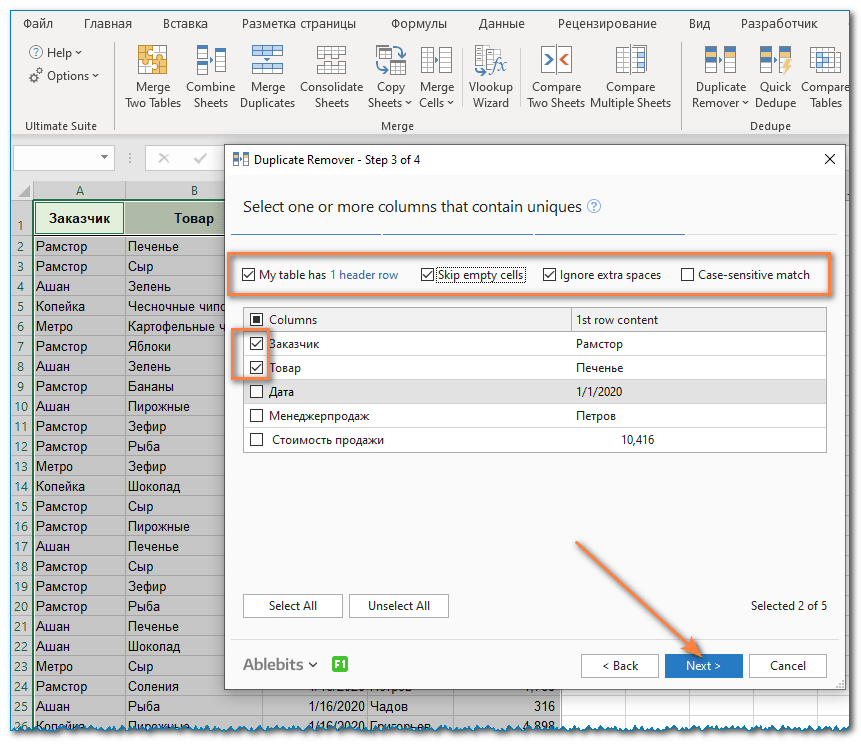
- Выберите действие, которое нужно выполнить над найденными значениями. Вам доступны следующие варианты:
- Чтобы выделить цветом.
- Выберите и подчеркните.
- Проверьте в столбце статуса.
- Скопируйте в другое место.
Чтобы не изменять исходные данные, выберите «Копировать в другое место», а затем укажите, где именно вы хотите видеть новую таблицу, на том же листе (выберите опцию «Выборочное местоположение» и укажите верхнюю ячейку целевого диапазона), на новом листе (Новый рабочий лист) или в новой рабочей книге (Новая рабочая книга).
В этом примере давайте выберем новый лист:
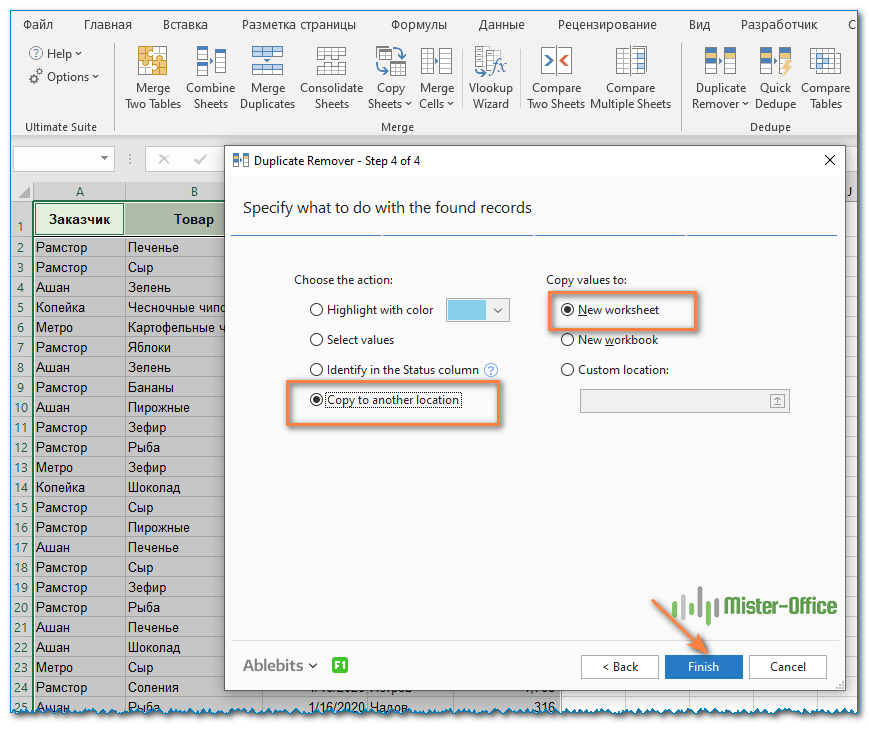
- Нажмите кнопку «Готово» и вуаля!
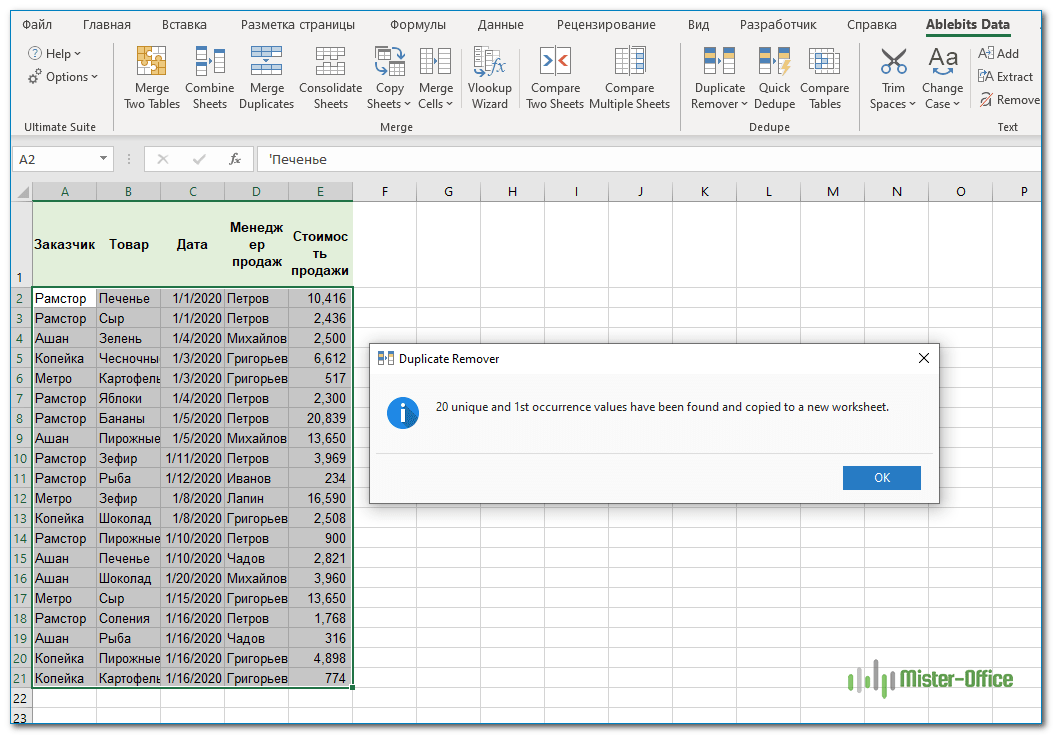
В итоге у нас осталось всего 20 билетов.
Вам нравится этот быстрый и простой способ получить список значений или уникальных записей в Excel? Если да, то я рекомендую вам загрузить полнофункциональную пробную версию Ultimate Suite и попробовать Duplicate Remover.
Ultimate Suite for Excel также включает множество других полезных инструментов, которые помогут вам сэкономить много времени. О них мы также подробно расскажем в других материалах сайта.